Evaluation Result Logs
The Logs section provides a detailed view of individual test case results from your AI Agent evaluation. This interface allows you to examine raw inputs, model outputs, and quality assessments for each test case, helping you understand your model's performance at a singular level.
Overview
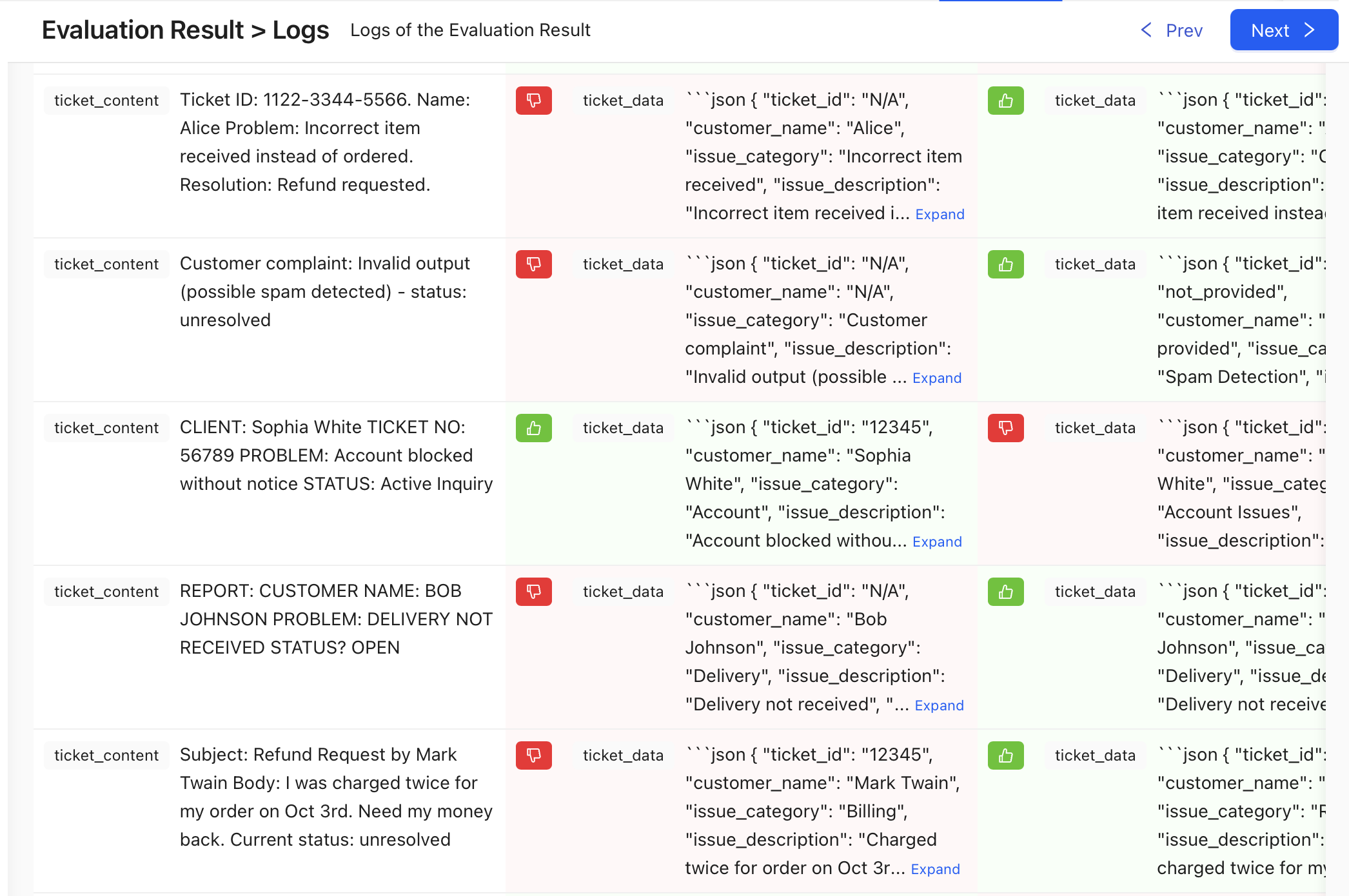
The Logs interface displays a table of evaluation results with the following components:
- Test Case: The identifier for each test case in your evaluation dataset
- Input: The original content provided to your model (e.g., ticket content)
- Simulation Result: The structured output generated by your AI Agent
- Quality Metrics: Performance ratings for various evaluation criteria
- Judge Reasoning: A detailed explanation for each rating
Comparing Models
Pairwise Evaluation configurations allow you to compare two Agents side-by-side:
- View responses from different models for the same input
- Compare quality ratings between models
- Identify where specific models excel or underperform
Related Features
For additional insights from your evaluation results, explore:
- Charts: Visual representations of overall performance metrics
- Report By Agent Data Scientist: AI-generated analysis with pattern recognition and recommendations