Evaluation Methodology: Pairwise
Method Overview
Pairwise Comparison is a structured evaluation method where two AI Agents generate responses to the same user input. Selected LLM Judges then compare these responses directly based on predefined evaluation metrics. This approach is highly effective for clearly identifying superior models, prompt configurations, or knowledge retrieval methods.
In Pairwise Comparison, every test case receives responses from two distinct LLM agents. Judges evaluate these two outputs according to detailed criteria specified in the evaluation metrics and then select the superior response. The judgment outcomes typically fall into 2 clear categories:
- Agent 1 Wins: Agent 1's response better fulfills the criteria than Agent 2's
- Agent 2 Wins: Agent 2's response better fulfills the criteria than Agent 1's
Notice: Tie is not possible, LLM Judge always has to select one superior response.
This direct head-to-head comparison provides clear insights into which model or configuration produces better outputs, simplifying decisions about which AI agent to adopt or optimize further.
Importance of Clear Evaluation Metrics
Same as grading system, the accuracy and reliability of Pairwise Comparison evaluations heavily depend on the clarity and precision of the defined metrics. Well-articulated metrics ensure consistent judgments across all test cases and judges, reducing subjective interpretations and ambiguity.
For guidance on creating strong, precise evaluation metrics inside AID, please refer to the Metrics Section in the Agent Instructions Document (AID).
Voting Ensemble for Increased Reliability
To further enhance evaluation precision and mitigate individual judge bias, Pairwise Comparison supports an ensemble voting mechanism. In this approach, multiple LLM Judges independently analyze each test case and select the superior agent response. Up to 5 LLM judges can independently vote for Agent 1 or Agent 2 based on the provided evaluation metrics. Each judge offers a reasoning behind their choice, adding transparency and interpretability to the decision-making process.
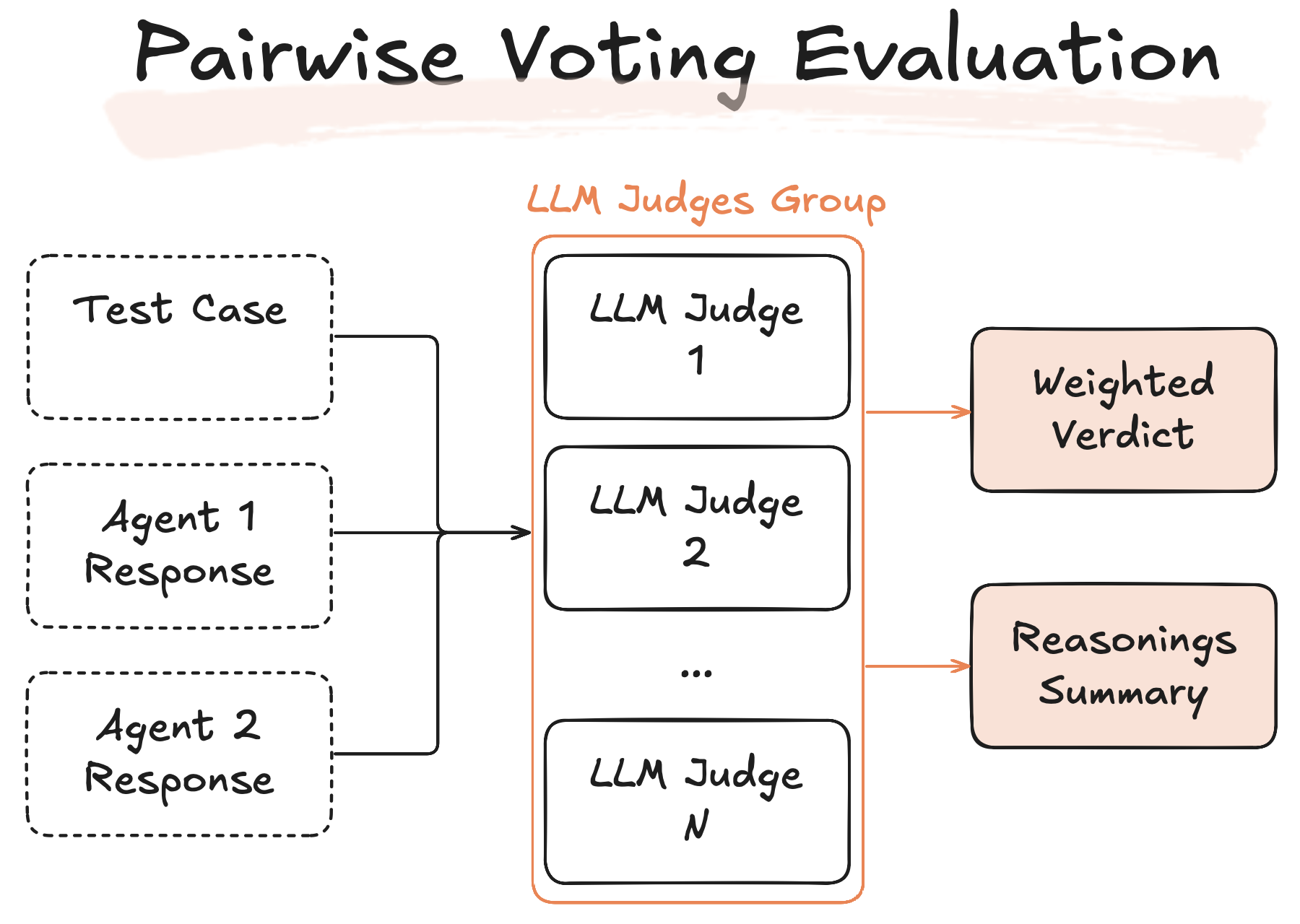
After voting, the system calculates the final outcome based on majority votes or weighted aggregation, delivering a comprehensive summary of the collective judgment along with detailed justifications provided by each judge.